Projects
Clinical Decision-Making in Delivery
Research has shown that many of the clinical decisions that are made under high pressure and in a short time frame rely on non-evidence-based simplified decision rules, resulting in suboptimal health outcomes. One of the settings, where this is prevalent, is the delivery room, where decision-making especially can have serious health consequences for both mothers and infants. This study investigated whether a physician’s decision in delivery mode for a current patient is influenced by the complication in the prior patient. I found that prior complications do influence physician’s decision-making in current delivery mode but were not able to ascertain the causation relationship between the complication in the prior patient and the delivery mode for the current patient.
Tools: Python (numpy, pandas, statsmodels, scikit-learn, scipy, matplotlib), SQL Server
When: January - April 2022
Medium Paper & Supplementary Materials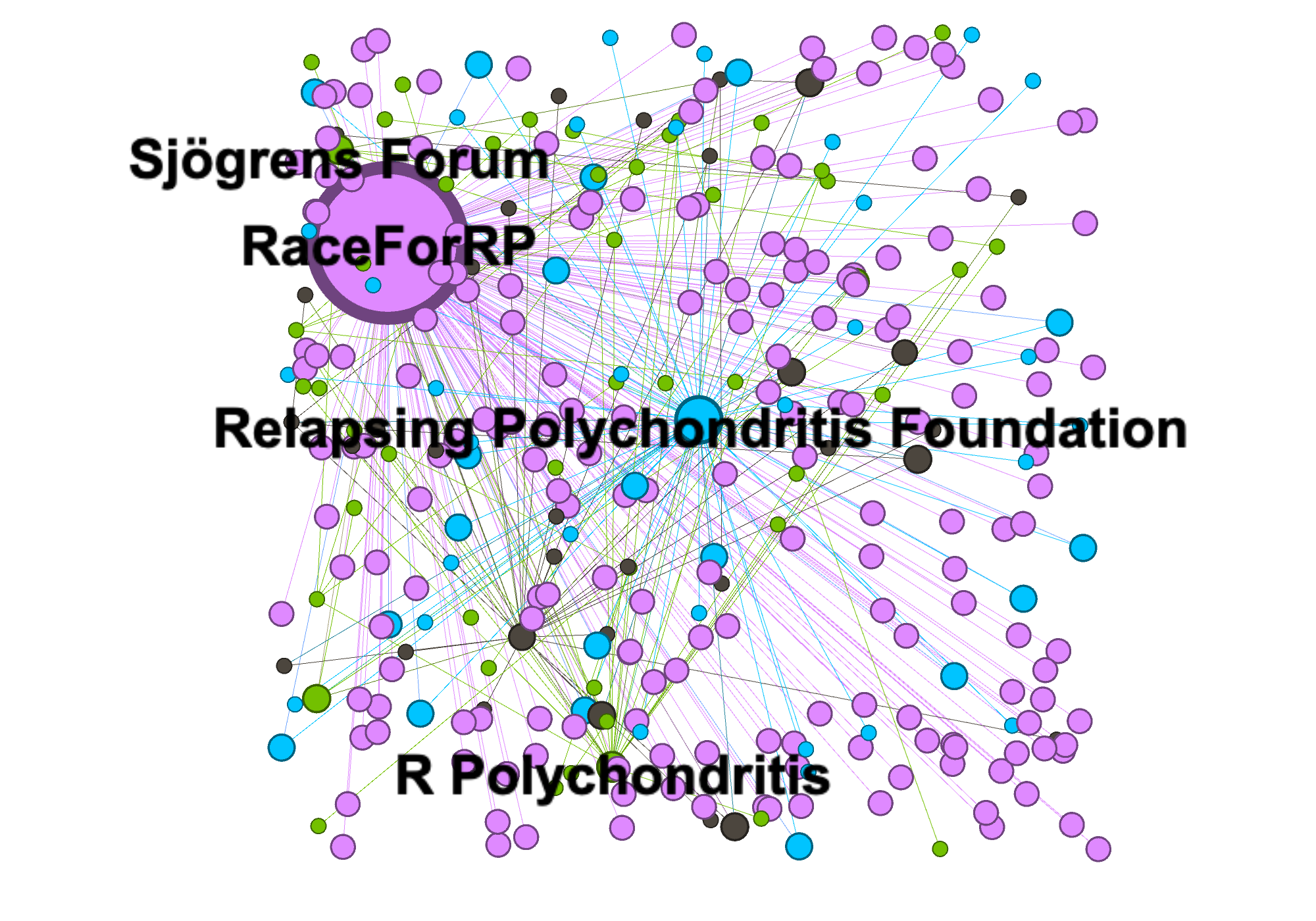
Relapsing Polychondritis in Twitter
In this project, I conducted tweet analyses to study conversations around relapsing polychondritis on social media. Relapsing polychondritis (RP) is a rare condition where there is not much discussion and awareness about its management, treatment and diagnosis. I used topic modeling method LDA and conducted network analyses to explore latent topics surrounding relapsing polychondritis in the tweets. This results showed that many of the tweets were focused on advocacy and raising awareness.
Tools: Python (numpy, pandas, gensim, nltk, scikit-learn, networkx), Gephi
When: October-December 2021
Medium Github Poster
Predicting Text Difficulty
I attempted to create a model that would predict text difficulty in a statement or sentence with high accuracy. For each statement or sentence, the model would predict whether it needs to be simplified or not simplified. This could potentially help build a tool that could aid editors, who simplify text and increase its readability of wikipedia pages for those who have learning/reading difficulties or have English as a second language.
Tools: Python (numpy, pandas, spacy, nltk, regular expressions, scikit-learn)
When: October-December 2021
Medium Github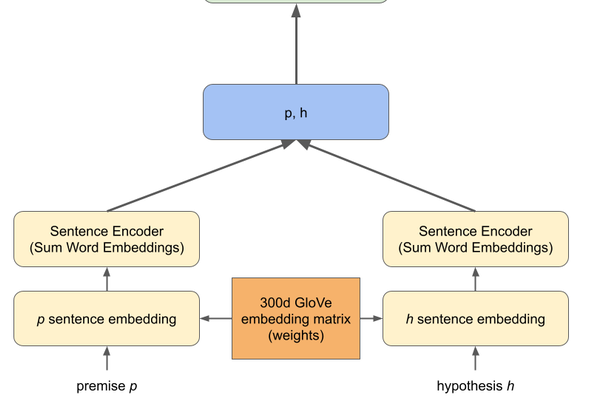
Natural Language Inference
This project shows implementation of the LSTM model and Sum Embedding models for the NLI task using the SNLI corpus. It was inspired by A large annotated corpus for learning natural language inference by Bowman et al. (2015) and Supervised Learning of Universal Sentence Representations from Natural Language Inference by Conneau et al. (2018).
Tools: Python (numpy, pandas, scikit-learn, Tensorflow)
When: March-April 2021
Medium Github
Medical Transcription Classification
The goal of this project is to develop or find high-performing NLP model that can correctly classify the medical specialties based on the transcription text with significant accuracy. This project was inspired by the existing Kaggle dataset Medical Transcriptions and mtsamples.com that has a collection of transcribed medical reports (Boyle, 2019). This project might be useful in understanding the nature of the language used in medical transcriptions of various kinds, and this tool might be useful for other kinds of NLP data analysis involving medical transcriptions.
Tools: Python (numpy, pandas, scikit-learn, xgboost, Keras)
When: March-April 2021
Medium Github Slides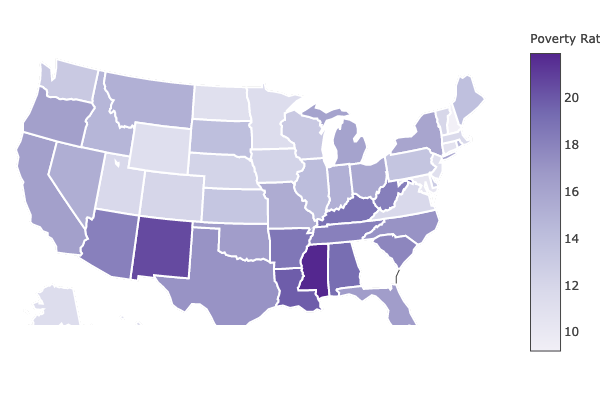
Human Trafficking Visualization
In this project, I took a look into the number of participating agencies that actively did something against human trafficking and the poverty rate in each state. Using the data, I created the choropleth map of United States, displaying the data of poverty rate and the state participation for each state. I gathered data using Web API and HTML parsing, and manipulated data using Python to produce cumulative data list. I visualized data by showing the poverty rate and the participation by state on US choropleth map using plotly.
Tools: Python (urllib, BeautifulSoup)
When: April 2017
Medium Github